STEM Curriculum Recommender
Project Overview
Motivation
The goal of this project is to streamline the process of matching educational content to specific topics in a curriculum. The aim is to develop an accurate and efficient model trained on a library of K-12 educational materials organized into various topic taxonomies.
These materials are in diverse languages and cover a wide range of topics, particularly in STEM (Science, Technology, Engineering, and Mathematics). The ultimate objective is to enable students and educators to more readily access relevant educational content to support and supplement learning.
What Was Done
Data Loading & Preprocessing
Loaded datasets, filtered for English content, focused on document/video/HTML5 formats, and dropped rows with missing values.
Text Preprocessing
Removed stopwords, links, special characters, and numbers. Converted text to lowercase and created a combined "corpus" column.
TF-IDF & Clustering
Applied TF-IDF vectorization to cleaned text data and used KMeans clustering with 2 clusters to group the content.
Visualization & Analysis
Reduced dimensionality using PCA for visualization, extracted top keywords for each cluster, and mapped clusters to labels.
What was Learned
Effectiveness of Clustering
The clustering was highly effective, achieving a 95% match for similar content.
Challenges Faced
Preprocessing challenges included handling missing values and removing irrelevant text elements. Clustering challenges involved determining optimal cluster numbers and ensuring meaningful separation.
What Was Achieved
- Filtered & preprocessed large STEM dataset
- Identified content clusters using TF-IDF & KMeans
- Extracted meaningful keywords for each cluster
- Created curriculum dataframe ready for recommendations
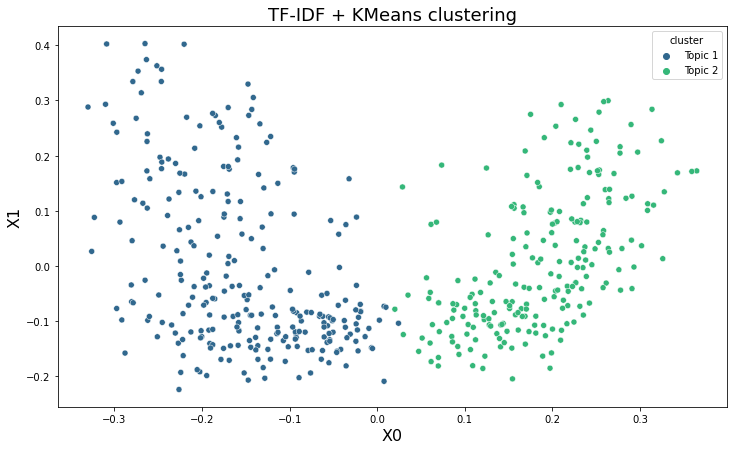
Visualization of content clusters